


Como se señaló en el primer artículo de esta serie, las estrategias y los procedimientos de recuperación ante desastres (DR) de TI ayudan a las organizaciones a proteger sus inversiones en sistemas e infraestructuras de TI.
La misión esencial de DR es devolver las operaciones de TI a un nivel aceptable de rendimiento lo más rápido posible después de un evento disruptivo.
Por lo tanto, al completar una evaluación de riesgos (RA) y un análisis de impacto comercial (BIA), debemos examinar los servicios de TI críticos necesarios para respaldar las actividades comerciales críticas de la organización.
En este artículo, veremos cómo establecer una estrategia de recuperación ante desastres y desarrollar planes de DR detallados.
Incorpore RPO y RTO en la estrategia DR
Antes de analizar la estrategia y la planificación de DR en detalle, debemos considerar dos métricas vitales, a saber, el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO).
De acuerdo con ISO/IEC 27031:2011, el estándar global para la recuperación de desastres de TI (referido como tecnología de la información y la comunicación, o TIC, en el estándar), RTO es “el período de tiempo dentro del cual los niveles mínimos de servicios y/o productos y los sistemas, aplicaciones o funciones de soporte deben recuperarse después de que haya ocurrido una interrupción”.
Mientras tanto, RPO es “el punto en el tiempo en el que se deben recuperar los datos después de que se haya producido una interrupción”. Ambas métricas son necesarias para definir las estrategias de DR.
RPO/RTO y la nube
Tenga en cuenta que estas dos métricas se ven afectadas por el uso de servicios basados en la nube y las consideraciones de seguridad cibernética.
Por ejemplo, el RTO para un centro de datos en el sitio puede ser más fácil de calcular, ya que todas las operaciones se encuentran dentro de la propia ubicación de la organización.
Por el contrario, cuando las operaciones de TI se descargan en servicios basados en la nube, el proveedor de la nube debe proporcionar RTO, que puede o no ofrecer un valor aceptable. Lo mismo ocurre cuando los datos se encuentran en un servicio en la nube.
Los sistemas de almacenamiento de datos en el sitio facilitan el soporte de los valores de RPO, mientras que los proveedores de almacenamiento en la nube fuera del sitio pueden no ser capaces de ofrecer un RPO confiable. Ambas preocupaciones hacen que un acuerdo de nivel de servicio (SLA) sólido sea muy recomendable, ya que establece niveles de rendimiento acordados que el tercero debe respaldar.
Estrategia y planes detallados en el proceso de planificación de DR
La Figura 1 representa las etapas del ciclo de vida de recuperación ante desastres de TI y está adaptada de la norma ISO 27031:2011. La figura muestra que, además del desarrollo de la estrategia, se deben considerar actividades adicionales antes de poder desarrollar los planes de DR.

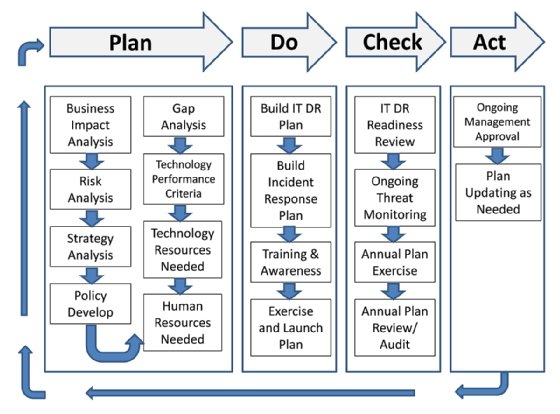
Por ejemplo, una política de recuperación ante desastres de TI es una parte esencial del proceso general de DR. Es, en particular, un elemento importante a examinar durante las auditorías, por lo que su desarrollo es fundamental.
Un análisis de brechas, que se puede realizar después de la evaluación de riesgos y las actividades de análisis de impacto comercial si es necesario, ayuda a identificar áreas de mejora que pueden mejorar el proceso general de planificación de recuperación ante desastres.
Los criterios de desempeño de la tecnología se pueden identificar a partir de BIA, RA y análisis de brechas, y se tendrán en cuenta en los planes de DR. Estas actividades también pueden identificar los recursos necesarios para lograr los niveles de desempeño deseados. Los BIA y los RA también deben tener en cuenta los recursos humanos, no solo durante un evento disruptivo, sino también durante las operaciones normales.
Definición de estrategia
Una vez que se han establecido y aprobado los sistemas y funciones críticos y los RTO y RPO, el siguiente paso es definir estrategias para responder a incidentes disruptivos cuando ocurran.
ISO 27031 establece: “Las estrategias deben definir los enfoques para implementar la resiliencia requerida para que se implementen los principios de prevención, detección, respuesta, recuperación y restauración de incidentes”.
Las estrategias definen “qué” se debe hacer al responder a un incidente, mientras que los planes describen “cómo” se realizarán las actividades de respuesta y recuperación.
Una vez que se hayan identificado los sistemas críticos, los datos, las redes, los elementos de seguridad cibernética y las empresas de servicios en la nube, use el ejemplo de la Tabla 1 como punto de partida para ayudar a formular las estrategias necesarias para protegerlos.

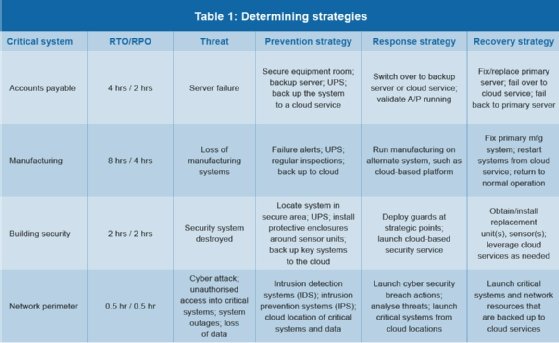
Los factores que se deben considerar al desarrollar una tabla de este tipo pueden incluir presupuestos; los puntos de vista de la gerencia con respecto a los riesgos; problemas de seguridad cibernética; disponibilidad de recursos, especialmente servicios en la nube; costos versus beneficios; limitaciones humanas; limitaciones tecnológicas; y requisitos reglamentarios.
Factores clave en la definición de la estrategia DR
Los siguientes son temas importantes al desarrollar estrategias de DR, especialmente cuando se considera el uso de servicios basados en la nube.
Consideraciones de personas
Entre los temas clave están la disponibilidad del personal y/o contratistas, las necesidades de capacitación del personal y los contratistas, la duplicación de habilidades críticas para que pueda haber una primaria y al menos una de respaldo, documentación disponible para ser utilizada por el personal y seguimiento para garantizar retención del conocimiento por parte del personal y del contratista.
El uso de servicios en la nube introduce consideraciones adicionales, como la seguridad de los datos y los sistemas, las calificaciones del personal del proveedor de la nube, la posibilidad de que los empleados de la nube deshonestos dañen o roben los recursos del cliente, la disposición de los representantes del proveedor de la nube para responder preguntas con sinceridad y la capacidad de la nube. personal del proveedor para manejar los requisitos del cliente.
Facilidades fisicas
Aquí, debemos considerar la disponibilidad de áreas de trabajo alternativas dentro del mismo sitio, en una ubicación diferente de la empresa, en una ubicación proporcionada por un tercero, en las casas de los empleados y en una instalación de trabajo transportable (como un remolque equipado para el trabajo). espacio).
También es importante tener en cuenta la seguridad del sitio, los procedimientos de acceso del personal, las tarjetas de identificación y la ubicación del espacio alternativo en relación con el sitio de la oficina principal. Es posible que no sea posible visitar físicamente las instalaciones del proveedor de la nube, y los sistemas y datos de los clientes se pueden almacenar en varios centros de datos, por lo que los usuarios deben estar preparados para confiar en los proveedores de la nube para proteger sus activos en centros de datos seguros y seguros para el medio ambiente.
Consideraciones tecnológicas
Esto incluye cosas como el acceso al espacio del equipo correctamente configurado para los sistemas (por ejemplo, pisos elevados), calefacción, ventilación y aire acondicionado (HVAC) adecuados, energía eléctrica principal suficiente, infraestructura de voz y datos adecuada, distancia del área de tecnología alternativa a la principal. sitio, provisión de personal en un sitio de tecnología alternativa, disponibilidad de tecnologías de conmutación por error (a un sistema de respaldo) y conmutación por recuperación (retorno a las operaciones normales) para facilitar la recuperación, la necesidad de admitir sistemas heredados y capacidades de seguridad física y de información en el sitio alternativo .
Cada uno de estos problemas debe abordarse cuidadosamente al utilizar un proveedor de servicios en la nube. Es recomendable incluirlos en los acuerdos de nivel de servicio (SLA) si es posible.
Consideraciones de datos
Aquí tenemos que incluir una copia de seguridad oportuna de los datos críticos en un área de almacenamiento segura de acuerdo con los requisitos de RTO/RPO, métodos de almacenamiento de datos (por ejemplo, disco, cinta, óptico), requisitos de conectividad y ancho de banda para garantizar que todos los datos críticos se puede realizar una copia de seguridad de acuerdo con los plazos de RTO/RPO, las capacidades de protección de datos en un sitio de almacenamiento alternativo y la disponibilidad de soporte técnico de proveedores de servicios externos calificados.
Estas consideraciones son esenciales cuando se utiliza un proveedor de servicios en la nube, especialmente sus recursos para almacenar y acceder a los sistemas y datos de los clientes, cómo protegen sus perímetros de red de ataques cibernéticos, cómo se adaptan a los requisitos de RTO/RPO de los clientes y cómo prueban sus propios planes de recuperación ante desastres. .
Consideraciones del proveedor
Aquí necesitamos identificar y contratar proveedores primarios y alternativos para todos los sistemas y procesos críticos, e incluso el abastecimiento de personas. Las áreas clave donde los proveedores alternativos serán importantes incluyen hardware (servidores, bastidores), energía (baterías, UPS, protección de energía), redes (servicios de red de voz y datos), reparación y reemplazo de componentes y múltiples empresas de entrega (Fedex y UPS) .
Muchos de estos problemas se pueden mitigar mediante el uso de un proveedor de servicios en la nube, pero aún así es prudente mantener copias de seguridad de datos y aplicaciones críticos y tener suministros de componentes críticos del sistema.
Policias y procedimientos
Los pasos clave aquí incluyen definir políticas para la recuperación de desastres de TI, hacer que la alta dirección las apruebe, definir procedimientos paso a paso (por ejemplo, para iniciar la copia de seguridad de datos en ubicaciones alternativas seguras), reubicar las operaciones en un espacio alternativo, recuperar sistemas y datos en los sitios alternativos, y la reanudación de las operaciones en el sitio original o en una nueva ubicación. Cuando utilice servicios en la nube, asegúrese de tener en cuenta las consideraciones relacionadas con la nube en todas las políticas de recuperación ante desastres y los documentos de procedimiento relacionados.
Finalmente, asegúrese de obtener la aprobación de la gerencia para las estrategias, políticas y procedimientos planificados. Esté preparado para demostrar que las estrategias propuestas se alinean con los objetivos comerciales y las estrategias de continuidad comercial de la organización.
Traducir estrategias en planes DR
El siguiente paso después de completar las estrategias de DR es traducirlas en planes y procedimientos de recuperación ante desastres. Para mostrar cómo se puede hacer esto, la Tabla 1 se ha convertido en la Tabla 2, que sigue.
Muestra los sistemas críticos y las amenazas asociadas, la estrategia de respuesta y los (nuevos) pasos de acción de respuesta, la estrategia de recuperación y los (nuevos) pasos de acción de recuperación. Realizar este paso ayuda a definir pasos de acción de alto nivel que forman parte del plan DR.

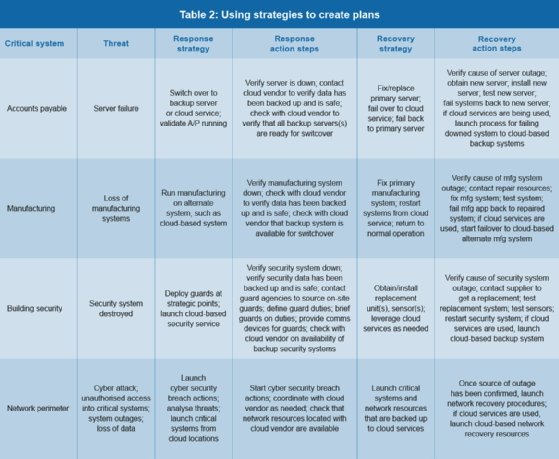
Utilice la Tabla 2 para expandir los pasos de acción de alto nivel en procedimientos detallados paso a paso, según sea necesario. Asegúrese de que estén vinculados en la secuencia adecuada.
Desarrollo de planes de DR
Los planes de recuperación ante desastres proporcionan un proceso paso a paso para responder a un evento disruptivo.
Los procedimientos deben garantizar un proceso repetible y fácil de usar para recuperar los activos de TI dañados y devolverlos a su funcionamiento normal lo más rápido posible. Si es necesaria la reubicación del personal en un hot site de terceros u otro espacio alternativo, se deben desarrollar procedimientos para esas actividades. Los pasos para usar los recursos de respaldo basados en la nube deben desarrollarse en coordinación con el proveedor de la nube, de modo que los procedimientos se realicen en la secuencia adecuada.
Considere también revisar los estándares globales ISO/IEC 24762 (Directrices para los servicios de recuperación de desastres de tecnología de la información y las comunicaciones) e ISO/IEC 27035 (Actividades de respuesta a incidentes) al desarrollar planes DR.
Respuesta al incidente
Además de utilizar las estrategias desarrolladas anteriormente, los planes de recuperación ante desastres de TI también deben incluir un proceso de respuesta a incidentes (ISO/IEC 27035) para abordar las fases iniciales del incidente y los pasos a seguir.
Como en la Figura 2, las acciones de respuesta a incidentes deben preceder a las acciones de recuperación ante desastres. Cuando se utilizan servicios en la nube, trabaje con el proveedor para incorporar sus actividades de respuesta a incidentes en el plan de DR.


Nota: La gestión de emergencias se ha incluido en la Figura 2, ya que representa actividades que pueden ser necesarias para abordar situaciones en las que las personas resultan heridas o situaciones como incendios que deben ser abordados por las brigadas de bomberos locales y otros socorristas.
La estructura del plan DR
La siguiente sección detalla el marco y los componentes para un plan DR basado en ISO 27031 e ISO 24762.
Los mejores planes de recuperación ante desastres a menudo comienzan con una o dos páginas que resumen los pasos de acción clave (por ejemplo, dónde reunir a los empleados si se ven obligados a evacuar el edificio) y listas de contactos clave (por ejemplo, proveedores de la nube, áreas de trabajo alternativas) y su información de contacto para facilitar la autorización y lanzamiento del plan.
Introducción
Después de las páginas iniciales de emergencia, los planes de DR tienen una introducción que incluye el propósito y el alcance del plan. Esta sección debe especificar quién ha aprobado el plan, quién está autorizado para activarlo e incluir una lista de enlaces a otros planes y documentos relevantes (por ejemplo, políticas).
Funciones y responsabilidades
La siguiente sección debe definir las funciones y responsabilidades de los miembros del equipo de DR, sus datos de contacto, los límites de gasto (por ejemplo, si se debe comprar equipo) y los límites de su autoridad en una situación de desastre. Cuando se utilizan servicios en la nube, estos mismos parámetros deben definirse para el proveedor de la nube.
Respuesta al incidente
El proceso de respuesta a incidentes identifica la presencia repentina de una situación fuera de lo normal (por ejemplo, alertada por varias alarmas a nivel del sistema), evalúa rápidamente la situación (y cualquier daño) para hacer una determinación temprana de su gravedad, intenta contener el incidente y ponerlo bajo control, y notifica a la gerencia, a los proveedores de servicios en la nube y a otras partes interesadas clave.
Activación de planes
Según los hallazgos de las actividades de respuesta a incidentes, el siguiente paso es determinar si se deben lanzar planes de recuperación ante desastres y cuáles en particular se deben invocar. Estos…